
Spark RDD(Resillient Distributed Data)
스파크의 데이터 구조
- RDD (Resillient Distributed Data)
- Dataframe
- Dataset
- RDD : 스파크 도입 초창기부터 적용되었던 가장 첫번째 데이터구조
RDD
- Resillient(회복력 있는, 변하지 않는) : 메모리 내부에서 데이터가 손실 시 유실된 파티션을 재연산해 복구할 수 있음
- Distributed(분산된) : 스파크 클러스터를 통하여, 메모리에 분산되어 저장됨
- Data : 파일, 정보 등
DAG(Directed Acyclic Graph)
- 직관적 방향성의 비순환 그래프, 즉 반복이 일어나지 않는 그래프
DAG에 의하여 특정 RDD 관련 정보가 정보가 메모리에서 유실되었을 경우, 그래프를 복기하여 다시 계산하고, 자동으로 복구가능- 스파크는 이러한 특성 때문에 Fault-tolerant(작업 중 장애나 고장이 발생하여도 예비 부품이나 절차가 즉시 그 역할을 대체 수행함으로써 서비스의 중단이 없게 하는 특성)를 보장한다.
- 노드간의 순환(cycle : 시작점과 끝점이 같은 형태)이 없으며, 각 노드 간에는 의존성이 있고 일정항 방향성을 가지고 있다.
- RDD는 회복력있는 분산형 데이터라는 뜻으로, RDD는 기본적으로
Read-Only로 수정 불가한 성격을 가지고 있다. - 그렇기 때문에 이를 변형하기 위해서는 다른 RDD가 생성이 되고 이러한 과정은
DAG(Directed Acyclic Graph)로 히스토리가 기록이 된다. 이때 이런 히스토리를Lineage(혈통)라고 부른다.
-> 특정 동작에 의해 생성되는 RDD Lineage는 DAG(Directed Acyclic Graph)의 형태를 가진다.
RDD 동작 원리
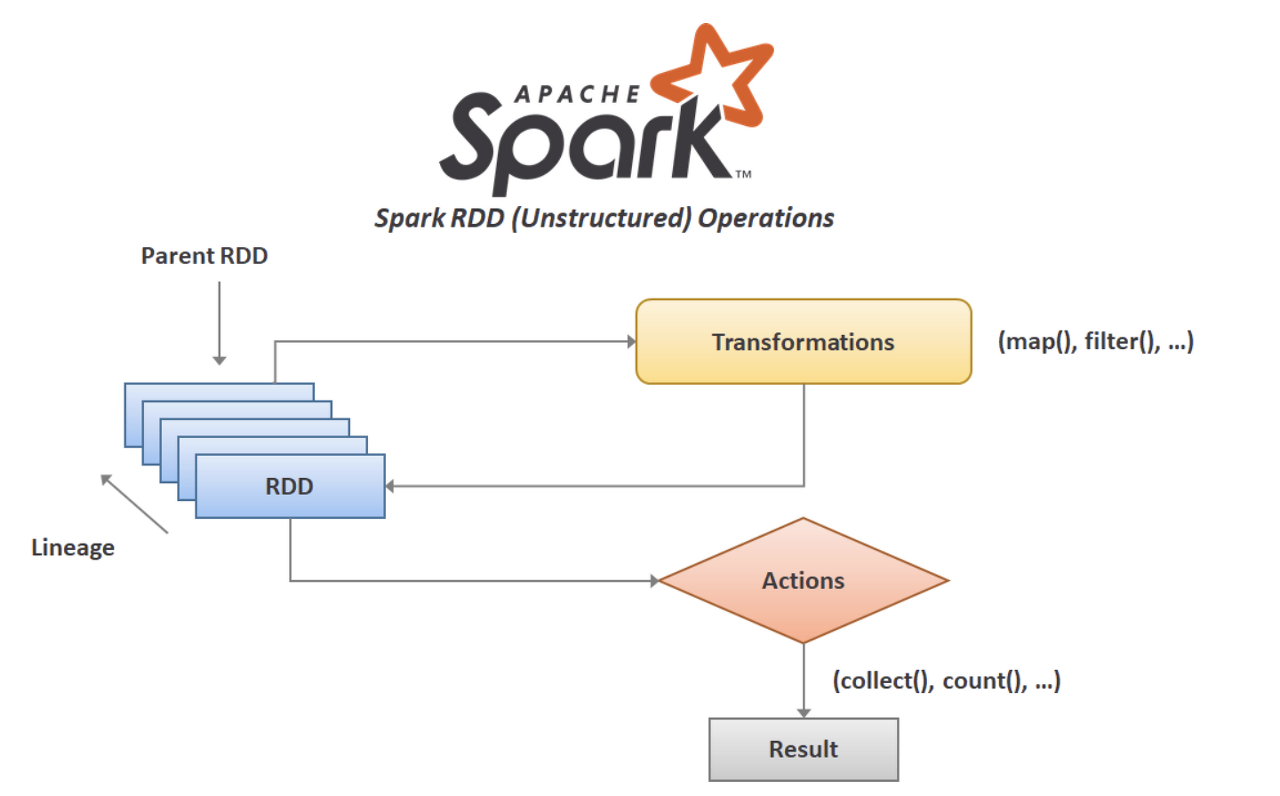
RDD의 Lineage 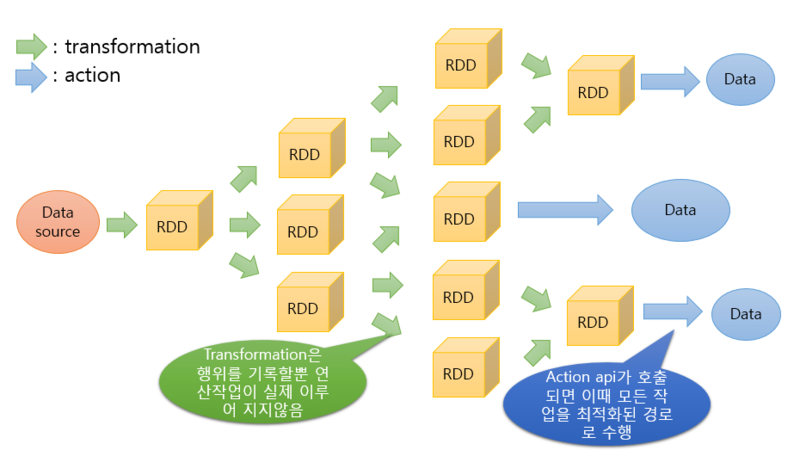
- RDD는 Transform을 수행하기 위해 DAG가 누적되지만 실제 물리적인 실행은 이루어지지 않는다.
- 클라이언트에서 실제 실행을 명령했을 때 위 그림상 Action() 분기를 만나 실제 수행하게 되는데 이때 RDD들의 DAG도 수행이 된다.
- 그렇기 때문에 중간 RDD과정에서의 데이터 유실이나 손상이 있더라도 원본데이터가 손상되지 않는 선에서 스파크는 데이터 복구가 용이하다.