
Spark란?
- Spark은 “General Purpose High Performance Distributed Platform (범용 목적의 분산 고성능 클러스터링)”이다.
- 빅데이터 처리를 위한 오픈소스 분산 처리 플랫폼
- Scala로 개발되었으며 Python/Java/R을 추가로 지원한다
spark 등장 배경
빅데이터의 개념이 등장하였을 당시,”빅데이터 처리 = 하둡(Hadoop)”이라고 할 정도로,하둡 에코시스템이 시장을 지배하였다. 하둡은 HDFS(Hadoop Distributed File System)라고 불리는, 분산형 파일 시스템을 기반으로 만들어졌으며, HDFS와 ‘맵리듀스’라고 불리는 대형 데이터셋 병렬 처리 방식에 의해 동작한다.
1) 하둡의 HDFS는 DISK I/O를 기반으로 동작하는데, 실시간성 데이터에 대한 니즈(NEEDS)가 급격하게 증가하면서, 하둡으로 처리하기에는 속도 측면에서 부적합한 시나리오들이 등장하였다. 2) 컴퓨터 H/W들의 가격이 빠른 속도로 다운되면서, 기존에 고가로 취급되던 메모리를 고용량으로 사용할 수 있게 되었다.
위의 문제를 개선하기 위해 등장 한 것이 ‘아파치 스파크’
- 아파치 스파크는 인메모리상에서 동작 하므로, 반복적인 처리가 필요한 작업에서 속도가 하둡보다 최소 1000배 이상 빠르며 이를 통해 데이터 실시간 스트리밍 처리라는 니즈를 충족
- 최근엔 하둡 + 스파크 연계방식으로 많이 사용하며 하둡의 YARN 위에 스파크를 얹고, 실시간성이 필요한 데이터는 스파크로 처리하는 방식으로, 대부분의 기업들과 연구단체에서 이와 같은 아키텍처를 구성하여 동작 중에 있다.
스파크의 구조 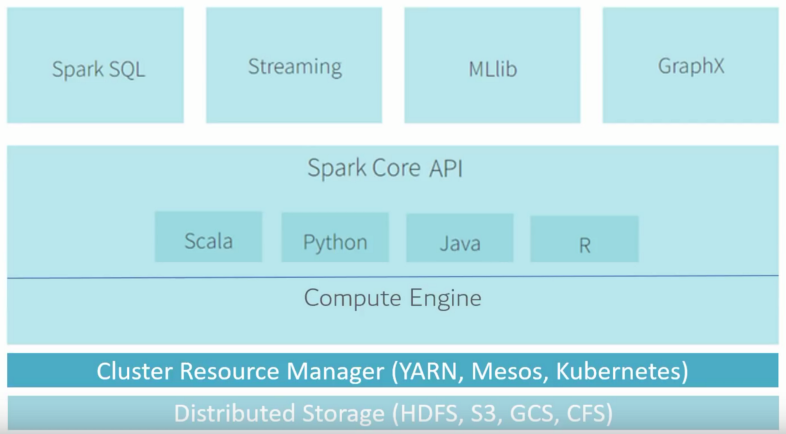
스파크의 다양한 컴포넌트와 라이브러리
Scala, JAVA, Pyhon등의 다양한 언어 기반의 고수준 API를 사용 가능하다.SQL의 기능을 담당하는Spark SQL- 여러 머신러닝 기법을 지원하는
MLlib, MLlib는 최근 크게 각광받고 있으며, 금융권 등 국내의 데이터 실시간 분석에서 스파크 비율이 압도적으로 높은 추세이다.

- 실시간 데이터 처리를 지원하는
Spark Streaming, spark streaming 은 Kafka, Hadoop과 연계 가능한 스파크의 확장성 덕분에, 위와 같은 구조로 대부분의 기업에서 활용되고 있다. 카프카, 플럼, 키네시스, TCP 소켓 등 다양한 경로를 통해서 데이터를 입력 받고, map, reduce, window 등의 연산을 통해 데이터를 분석하여 최종적으로 파일시스템, 데이터베이스 등에 적재한다.
Spark Application
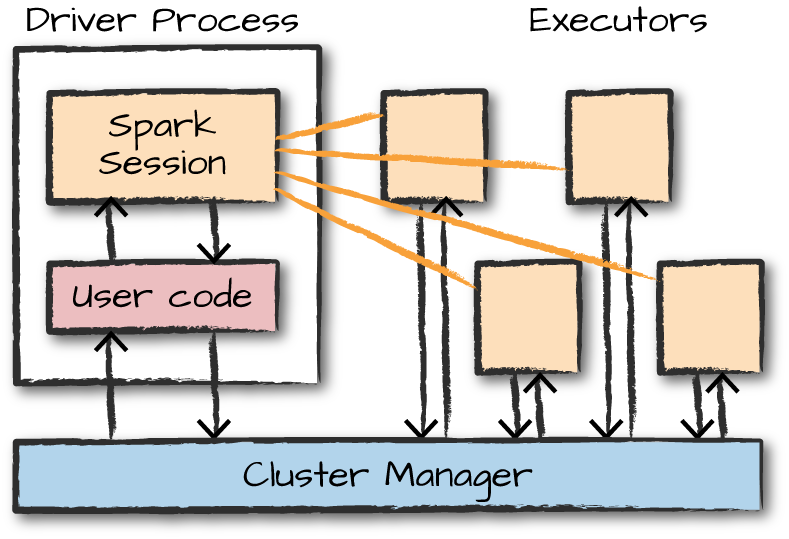
Spark Driver
- 한 개의 노드에서 실행되며, 스파크 전체의 main() 함수를 실행
- 어플리케이션 내 정보의 유지 관리, 익스큐터의 실행 및 실행 분석, 배포 등의 역할을 수행
- 사용자가 구성한 사용자 프로그램(Job)을 task 단위로 변환하여, Executor로 전달
Executor
- 다수의 worker 노드에서 실행되는 프로세스
- Spark Driver가 할당한 작업(task)을 수행하여 결과를 반환 하거나 블록매니저를 통해 cache하는 RDD를 저장한다
Cluster Manager
- 클러스터 매니저는 스파크와 붙이거나 뗄 수 있는, Pluggable한 컴포넌트로, 스파크 어플리케이션의 리소스를 효율적으로 분배하는 역할
- 스파크는 익스큐터를에 태스크를 할당하고 관리하기 위하여 클러스터 매니저에 의존
- 이 때, 스파크는 클러스터 매니저의 상세 동작을 알지 못한다.(Black-box) 단지 클러스터 매니저와의 통신을 통하여, 할당 가능한 Executor를 전달받는다.
- 스파크 3.0 기준으로, 사용 가능한 클러스터 매니저에는 Spark StandAlone, (Hadoop)Yarn, Mesos, Kubernetes 등이 있다.
Spark StandAlone
- 클러스터가 아닌 단일 컴퓨터에서 스파크 전체를 동작시키는 방식
- 이 때 Spark Driver와 Executor는 각각 thread로 동작
- Worker 노드에 여러개의 Executor를 실행시킬 수 있는 Yarn, Mesos, K8s와 달리, StandAlnoe 모드의 경우 Executor는 Worker 노드 하나당 한개 씩 동작
Spark Application 실행 과정
Spark application : 클러스터에서 독립된 프로세스들의 묶음으로 동작하며, 메인 프로그램(driver Program)의 SparkContext object에 의해서 조정된다.
- Driver Program(프로세스)가 main을 실행시키며 SparkContext 생성한다.
- SparkContext가 Cluster Manager에 연결된다.
- 연결되면, 클러스터 내의 Executor를 할당받는다.
- SparkContext가 application code(SparkContext에 전달된 Jar 또는 Python file)를 executor에 보낸다.
- SparkContext가 실행할 task를 executor에 보낸다.
요약 : 사용자 프로그램을 수행하기 위하여, Spark Driver 내의 Spark Context가 Job을 task 단위로 쪼갠다. Cluste Manager로부터 할당받은 Executor로 task를 넘긴다.