
Hadoop Echo System
- 하둡에서 데이터를 분석 유지 저장 관리 할 때 필요한 모든 것들
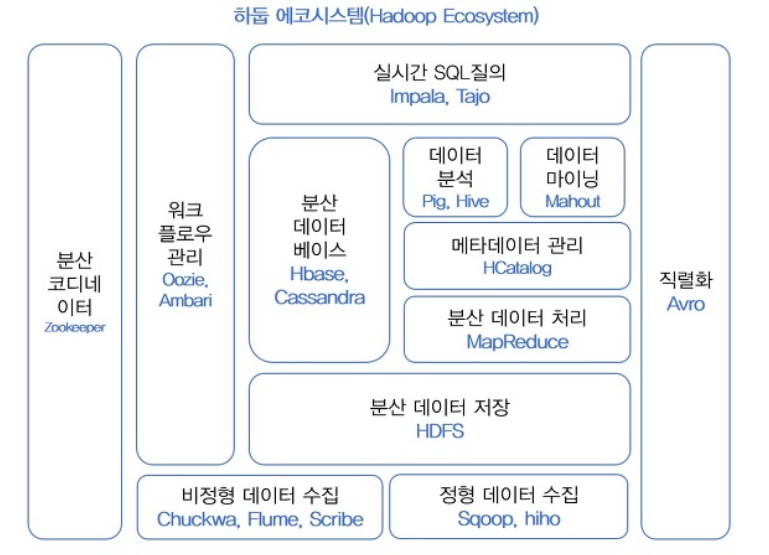
작업 구분별 주요 기술
| 구분 | 주요 기술 |
|---|---|
| 데이터 수집 | 플럼(Flume), 스쿱(Sqoop) |
| 데이터 저장,활용 | Hbas |
| 데이터 처리 | 하이브(Hive),피그(Pig),마후트(Mahout) |
| 데이터 관리 | 우지(Oozie), H카탈로그(HCatalog), 주키퍼(Zookeeper) |
작업 흐름도 1) HDFS(하둡 저장 시스템) 2) MapReduce(데이터를 key value로 변경) 3) Hbase(변경된 데이터를 데이터베이스로 저장) 4) Pig, Hive, Mahout, Oozie(데이터를 분석)
하둡 사용자 인터페이스(Hue, Zeppelin)
하둡 휴(Hue, Hadoop User Experience)
- 하둡과 하둡 에코시스템의 지원을 위한 웹 인터페이스를 제공하는 오픈 소스
- Hive 쿼리를 실행하는 인터페이스를 제공하고, 시각화를 위한 도구를 제공
- job의 스케줄링을 위한 인터페이스와 job, HDFS, 등 하둡을 모니터링하기 위한 인터페이스도 제공
Zeppelin
- Zeppelin은 한국의 NFLab이라는 회사에서 개발하여 Apache top level 프로젝트로 최근 승인
- 오픈소스 솔루션으로, Notebook 이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, Query 등을 실행하고 결과를 웹에 나타내는 솔루션
Pig 와 Hive Project
- Pig : [Yahoo] 많은 사람들이 사용할 수 있도록 MapReduce 프로그램을 만들어 주는 고수준 언어를 만들겠다는 목적으로 만들어짐
- HIVE : [Facebook] SQL(유사) 구문에서 MapReduce를 자동생성하겠다는 목적으로 만들어짐
YARN(Yet Another Resource Negotiator)
- YARN은 Hadoop v1에 있던 Job Tracker의 병목현상을 제거하기 위해 Hadoop v2에 도입
- 가장 효율적인 방법으로 계산 리소스를 할당하고 사용자 애플리케이션을 스케줄링하는 시스템
- YARN은 빅데이터 처리에 사용되는 대규모 분산 운영체제 라고도 할 수 있다.
- 다양한 데이터 처리 엔진을 통해 HDFS (Hadoop 분산 파일 시스템)에 저장된 데이터를 실행하고 처리
YARN 주요 컴포넌트
- Resource Manager : 자원을 시스템의 응용프로그램(Application)에 할당이 가능하다.
- Nodes Manager : CPU, 메모리 같은 자원의 할당된 것을 일하고 Resource Manager에 보고한다.
- Application Manager : Resource Manager와 Nodes Manager 간의 인터페이스 역할을 한다.